深度学习的实用层面
数据集划分:训练/验证/测试
应用深度学习/机器学习是一个不断迭代的过程。
对于一个实际问题的样本数据,在建立模型的过程中,数据集会被划分为如下部分:
- 训练集:对模型进行训练,学习模型的参数;
- 验证集:用于交叉验证,选择最好的模型;
- 测试集:对学习到的模型进行测试,获取模型运行的无偏估计。
对小数据情况(如:100、1000、10000)数据集通常按照如下比例划分:
- 无验证集:70% / 30%;
- 有验证集:60% / 20% / 20%。
对大数据情况,数据规模可能是百万级别的,验证集和测试集所占的比重会趋向于更小。验证集的目的是选择最好的模型,验证集只要足够大到验证大约2-10种模型,不需要20%数据集,例如在百万级别数据中,选1万数据作为验证集就行。大数据集的的划分可以按照如下划分(建议):
- 100万数据:98% / 1% / 1%;
- 更多数据:99.5% / 0.25% / 0.25%。
建议:要确保验证集和测试集的数据来自同一分布。
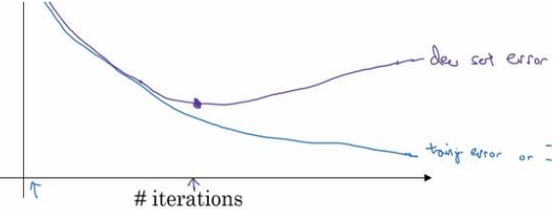
偏差/方差
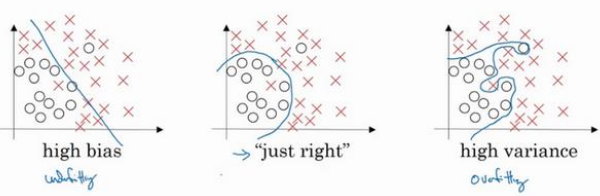 在深度学习(或机器学习)中,偏差和方差的解释如下:
在深度学习(或机器学习)中,偏差和方差的解释如下:
- 偏差:可通过训练误差(train set error)反映,当训练误差大时,说明当前模型偏差高,模型存在欠拟合;
- 方差:可通过验证误差(dev set error)反映,当验证误差大时,说明当前模型方差高,模型存在过拟合。
好的模型应该是偏差和方差都小。
存在高偏差:
- 训练更大的网络(添加隐藏层或隐藏单元数目或更大的神经网络结构);
- 增加训练时间(不一定有效)。
存在高方差:
- 增加样本数据;
- 添加正则化(regularization);
- 寻找更加合适的网络结构。
正则化(regularization)
深度学习可能存在过拟合问题–高方差,有两个解决方法,一个是正则化,一个是准备更多数据。正则化是在成本函数中添加一个正则化项,限制模型的复杂度。
Logistic回归中正则化
对于Logistic regression,加入L2正则化(也称L2范数)的代价函数:$$J(w,b)=\dfrac{1}{m}\sum_{i=1}^{m}L(\widehat {y}^{(i)},y^{(i)})+\dfrac{\lambda}{2m}||w||_2$$其中L2正则化:$$\dfrac{\lambda}{2m}||w||_2 =\dfrac{\lambda}{2m}\sum _{j=1}^{n_x}w_j^2 =\dfrac{\lambda}{2m}w^T w$$有时也使用L1正则化:$$\dfrac{\lambda}{2m}||w||_1 =\dfrac{\lambda}{2m}\sum _{j=1}^{n_x}|w_j|$$上式中\(\lambda\)是正则化因子,是超参数(通常使用验证集或交叉验证集来配置这个参数)。
如果用L1正则化,参数\(w\)最终会是稀疏的,就是说\(w\)中有很多\(0\)。在训练网络时,越来越倾向于使用L2正则化。
注意:lambda在Python中属于保留字段,所有在编程时候,使用lambd代替正则化因子。
神经网络中的正则化
避免过拟合的标准的方式添加L2正则化项,需修改代价函数:$$J=-\dfrac{1}{m}\sum _{i=1}^{m}\Big ( y^{(i)}\log(a^{[L]\left (i\right )})+(1-y^{(i)})\log(1-a^{[L]\left (i\right )})\Big )$$为$$J _{regularized} =\underbrace {-\dfrac{1}{m} \sum _{i = 1}^{m} \Big (y^{(i)}\log(a^{[L]\left (i\right )}) + (1-y^{(i)})\log(1- a^{[L]\left (i\right )}) \Big )} _\text {cross-entropy cost} + \underbrace {\dfrac{\lambda}{2m} \sum _{l=1}^{L}\sum _{k=1}^{n^{[l-1]}}\sum _{j=1}^{n^{[l]}} W _{k,j}^{[l] 2}} _\text {L2 regularization cost}$$
权重衰减(Weight decay)
对于神经网络,加入正则化项后,梯度变为(反向传播用到):$$dW^{[l]}=\dfrac{\partial L}{\partial {W^{[l]}}}+\dfrac{\lambda}{m}W^{[l]}$$得到梯度更新公式:$$W^{[l]}=W^{[l]}-\alpha dW^{[l]}$$可得:$$W^{[l]}=W^{[l]}-\alpha \Big [\dfrac{\partial L}{\partial {W^{[l]}}}+\dfrac{\lambda}{m}W^{[l]}\Big ]$$$$ =W^{[l]}-\alpha \dfrac{\lambda}{m}W^{[l]}-\alpha \dfrac{\partial L}{\partial {W^{[l]}}}$$$$ =(1-\dfrac{\alpha \lambda}{m})W^{[l]}-\alpha \dfrac{\partial L}{\partial {W^{[l]}}}$$其中,由于\(1-\dfrac{\alpha \lambda}{m} < 1\),会给原来的\(W^{[l]}\)一个衰减系数,因此L2正则化称为权重衰减(Weight Decay)。
正则化减小过拟合的原因
直观解释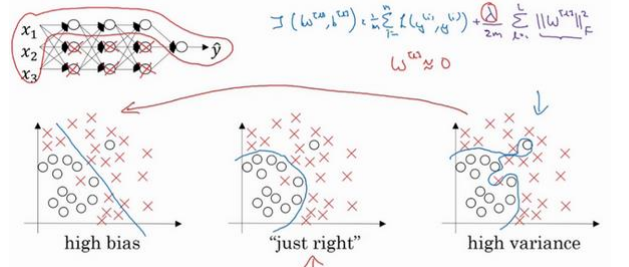 如果正则化\(\lambda\)设置的足够大,权重矩阵\(W\)会被设置接近\(0\),直观理解是把隐藏单元的权重设置为\(0\),于是基本上消除了这些隐藏单元的影响。会简化神经网络为小的网络,使得网络从过拟合的状态更接近左图的高偏差状态。
如果正则化\(\lambda\)设置的足够大,权重矩阵\(W\)会被设置接近\(0\),直观理解是把隐藏单元的权重设置为\(0\),于是基本上消除了这些隐藏单元的影响。会简化神经网络为小的网络,使得网络从过拟合的状态更接近左图的高偏差状态。
另一种解释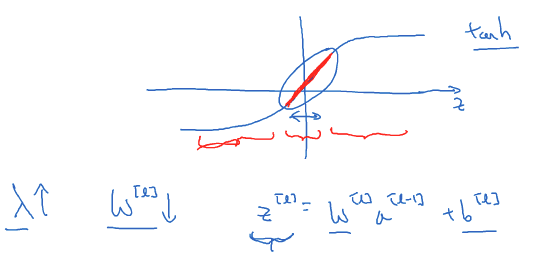 假设使用的激活函数是\(g(z)=\tanh(z)\)(
假设使用的激活函数是\(g(z)=\tanh(z)\)(sigmoid同理),加入正则化项后,当\(\lambda\)增大时,使得\(W^{[l]}\)减小,\(Z^{[l]}=W^{[l]}a^{[l-1]}+b^{[l]}\)会变小,根据上图可知,当\(z\)较小时,函数\(\tanh(z)\)近似线性,每层的激活函数近似线性使得整个网络进行线性,不会发生过拟合。
dropout 正则化
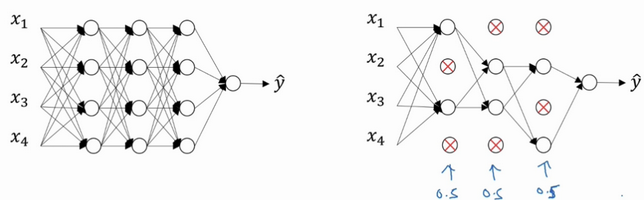
dropout(随机失活)在每次迭代中随机关闭一些神经元,保留下来的神经元形成一个结点较少、规模较小的网络用于训练。
At each iteration, you shut down (set to zero) each neuron of a layer with probability
1-keep_prob or keep it with probabilitykeep_prob(50% here). The dropped neurons don’t contribute to the training in both the forward and backward propagations of the iteration.
\(1^{st}\) layer: we shut down on average 40% of the neurons. \(3^{rd}\) layer: we shut down on average 20% of the neurons.
When you shut some neurons down, you actually modify your model. The idea behind drop-out is that at each iteration, you train a different model that uses only a subset of your neurons. With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time.
反向随机失活(Inverted dropout)Inverted dropout是最常用的实现dropout的方法。对第1层实现dropout:1
2
3
4
5keep_prob = 0.8 #设置神经元保留概率
d1 = np.random.rand(a1.shape[0], a1.shape[1]) < keep_prob
a1 = np.multiply(a1, d1)
a1 /= keep_prob
# 注:d1是一个布尔型数组,python会自动把True和False翻译为1和0
在最后一步执行a1 /= keep_prob是因为\(a^{[1]}\)减少比例为keep_prob,也就是说\(a^{[1]}\)中有比例为keep_prob的元素归零,为了不影响下一层\(z^{[2]}=W^{[2]}a^{[1]}+b^{[2]}\)的期望值,需要\(W^{[2]}a^{[1]}/keep\_prob\)。
注意:在测试阶段不要使用dropout,因为那样会使预测结果变的随机。
理解 dropout
加入了dropout后,输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,即不会给任何一个输入特征设置太大的权重。通过传播过程,dropout将产生和L2正则化相同的收缩权重的效果。
对于不同的层,设置的keep_prob也不同。一般来说,神经元较少的层,会设keep_prob为1.0,而神经元多的层则会设置比较小的keep_prob。dropout的一大缺点是成本函数无法被明确定义。因为每次迭代都会随机消除一些神经元结点的影响,因此无法确保成本函数单调递减。因此,使用dropout时,先将keep_prob全部设置为1.0后运行代码,确保J(w,b)函数单调递减,再打开 dropout。
其他正则化方法
- 数据扩增(Data Augmentation):通过图片的一些变换(翻转,局部放大后切割等),得到更多的训练集和验证集。
- 早停止法(Early Stopping):将训练集和验证集进行梯度下降时的成本变化曲线画在同一个坐标轴内,在两者开始发生较大偏差时及时停止迭代,避免过拟合。这种方法的缺点是无法同时达成偏差和方差的最优。
归一化输入(Normalizing inputs)
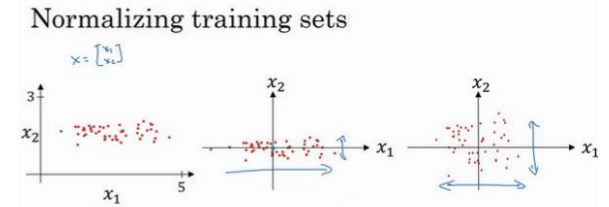 包含两步:零均值化和归一化。公式如下:$$x=\dfrac{x-\mu }{\sigma }$$其中$$\mu = \dfrac{1}{m}\sum _{i=1}^{m}x^{(i)}$$$$\sigma = \sqrt {\dfrac{1}{m}\sum _{i=1}^{m}x^{(i) 2}}$$经过归一化后每个特征的方差都变为\(1\)。注意,测试集和训练集用相同的参数\(\mu \)和\(\sigma \)进行数据归一化。
包含两步:零均值化和归一化。公式如下:$$x=\dfrac{x-\mu }{\sigma }$$其中$$\mu = \dfrac{1}{m}\sum _{i=1}^{m}x^{(i)}$$$$\sigma = \sqrt {\dfrac{1}{m}\sum _{i=1}^{m}x^{(i) 2}}$$经过归一化后每个特征的方差都变为\(1\)。注意,测试集和训练集用相同的参数\(\mu \)和\(\sigma \)进行数据归一化。
使用归一化的原因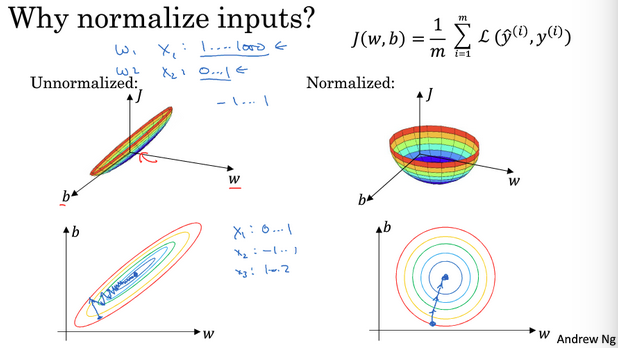 使用归一化后代价函数看起来更加对称。如果不使用归一化,需要设置一个非常小的学习率,因为初始值在某些位置时,梯度下降法可能需要更多次的迭代;如果归一化后,不论从哪个位置开始梯度下降法,可以更快找到最小值,可以在梯度下降中使用较大的步长。
使用归一化后代价函数看起来更加对称。如果不使用归一化,需要设置一个非常小的学习率,因为初始值在某些位置时,梯度下降法可能需要更多次的迭代;如果归一化后,不论从哪个位置开始梯度下降法,可以更快找到最小值,可以在梯度下降中使用较大的步长。
梯度消失和梯度爆炸(Vanishing / Exploding gradients)
在梯度函数上出现的以指数级递增或者递减的情况分别称为梯度爆炸或者梯度消失。
假定\(g(z)=z, b^{[l]}=0\),对应的输出为:$$\widehat y = W^{[L]}W^{[L-1]}\ldots W^{[2]}W^{[1]}$$
- 当\(W^{[l]}\)值大于\(1\)时,激活函数值以指数级递增;
- 当\(W^{[l]}\)值小于\(1\)时,激活函数值以指数级递减。
对于导数同理。在计算梯度时,根据不同情况梯度函数会以指数级递增或递减,导致训练难度上升,当梯度很小时,梯度下降算法的步长会变得非常小,需要训练的时间将会非常长。
神经网络权重初始化
对于出现的梯度消失或梯度爆炸问题,有一个不完整的解决方案(但有效)是谨慎选择随机初始化参数。
根据(只有一个神经元的网络,\(b=0\) ):$$z=w_1 x_1 + w_2 x_2 +\ldots w_n x_n$$为预防\(z\)过大或过小,当\(n\)越大,则\(w_i\)应该越小。合理的方法是设置\(w_i =\dfrac{1}{n}\)其中\(n\)表示神经元的输入特征量(对于只有一个神经元的网络)。
对于有多层的神经网络,设置某层\(W^{[l]}\)的权重为:$$W^{[l]} = np.random.randn(W^{[l]}.shape) * np.sqrt(\dfrac {1}{n^{[l-1]}})$$其中\(n^{[l-1]}\)是第\(l-1\)层的神经元数量。
如果某一层 \(l\) 的激活函数是 Relu 则初始化使用 np.sqrt( \(\dfrac{2}{n^{[l-1]}}\) )效果会更好;当某一层 \(l\) 的激活函数是 tanh 则初始化使用 np.sqrt( \(\dfrac{1}{n^{[l-1]}}\) ),有时也使用 np.sqrt( \(\dfrac{2}{n^{[l-1]}+ n^{[l]}}\) )。
梯度检验(Gradient checking)
导数或梯度的定义如下(双边误差求导):$$\dfrac{\partial J}{\partial \theta} = \lim_{\varepsilon \to 0} \dfrac{J(\theta + \varepsilon) - J(\theta - \varepsilon)}{2 \varepsilon}$$进行梯度检验时需要连接参数,将参数\(W^{[1]}, b^{[1]}, \ldots , W^{[L]}, b^{[L]}\)全部连接,形成一个向量\(\theta \),如下:$$J(W^{[1]}, b^{[1]}, \ldots , W^{[L]}, b^{[L]})=J(\theta )$$同时对\(dW^{[1]}, db^{[1]}, \ldots , dW^{[L]}, db^{[L]}\)执行同样的操作得到向量\(d\theta \),其与\(\theta \)有相同的维度。 求一个梯度的逼近值:$$d\theta _\text {approx}[i]=\dfrac{J(\theta _1 ,\theta _2 ,\ldots ,\theta _i +\varepsilon ,\ldots )-J(\theta _1 ,\theta _2 ,\ldots ,\theta _i -\varepsilon ,\ldots )}{2\varepsilon}$$应该:$$\approx d\theta [i] =\dfrac{\partial J}{\partial \theta _i }$$因此,利用梯度检验值:$$\dfrac{||d\theta _\text {approx} -d\theta || _2}{||d\theta _\text {approx}|| _2 +||d\theta || _2}$$其中:$$||x || _2 =(\sum _{i=1}^{m}|x _i | ^2)^{\dfrac {1}{2}}$$表示
求一个梯度的逼近值:$$d\theta _\text {approx}[i]=\dfrac{J(\theta _1 ,\theta _2 ,\ldots ,\theta _i +\varepsilon ,\ldots )-J(\theta _1 ,\theta _2 ,\ldots ,\theta _i -\varepsilon ,\ldots )}{2\varepsilon}$$应该:$$\approx d\theta [i] =\dfrac{\partial J}{\partial \theta _i }$$因此,利用梯度检验值:$$\dfrac{||d\theta _\text {approx} -d\theta || _2}{||d\theta _\text {approx}|| _2 +||d\theta || _2}$$其中:$$||x || _2 =(\sum _{i=1}^{m}|x _i | ^2)^{\dfrac {1}{2}}$$表示L2范数。
如果梯度检验值和\(\varepsilon \)的值相近,说明神经网络的实施是正确的,否则要去检查代码是否存在bug。
神经网络使用梯度检验注意事项
- 不要在训练中使用梯度检验,它只用于调试(
debug)。使用完毕关闭梯度检验的功能; - 如果算法的梯度检验失败,要检查所有项,并试着找出
bug,即确定哪个\(d\theta _\text {approx}[i]\)与dθ的值相差比较大; - 当成本函数包含正则项时,也需要带上正则项进行检验;
- 梯度检验不能与
dropout同时使用。因为每次迭代过程中,dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的成本函数J。建议关闭dropout,用梯度检验进行双重检查,确定在没有dropout的情况下算法正确,然后打开dropout;
优化算法
机器学习是一个经验过程,伴随大量的迭代过程,优化算法可以帮助快速训练模型。
Mini-batch 梯度下降(Mini-batch gradient descent)
batch 梯度下降法(批梯度下降法):同时处理整个训练集,当训练集很大时,处理速度会变慢。
Mini-batch 梯度下降(小批量梯度下降法):每次同时处理单个mini-batch(训练数据集的一部分),其他与batch梯度下降法一致。
使用batch梯度下降法,对整个训练集的一次遍历只能做一次梯度下降;使用mini-batch梯度下降法对整个训练集的一次遍历(称为一个epoch)可以做mini-batch个数个梯度下降。之后可多次遍历数据集,直到收敛到一个合适的精度。
考虑一个极端情况,当mini-batch个数为\(1\)(一个mini-batch只包含一个样本),对应的算法称为随机梯度下降法(Stochastic Gradient Descent--SGD)。对比于batch下降法的区别主要是:每一次的梯度计算仅仅针对一个训练样本,而不是整个训练集( What changes is that you would be computing gradients on just one training example at a time, rather than on the whole training set )。下面的程序说明了SGD和GD算法的差异:
(Batch) Gradient Descent
1
2
3
4
5
6
7
8
9
10
11
12X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in range(0, num_iterations):
# Forward propagation
a, caches = forward_propagation(X, parameters)
# Compute cost.
cost = compute_cost(a, Y)
# Backward propagation.
grads = backward_propagation(a, caches, parameters)
# Update parameters.
parameters = update_parameters(parameters, grads)Stochastic Gradient Descent
1
2
3
4
5
6
7
8
9
10
11
12
13X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in range(0, num_iterations):
for j in range(0, m):
# Forward propagation
a, caches = forward_propagation(X[:,j], parameters)
# Compute cost
cost = compute_cost(a, Y[:,j])
# Backward propagation
grads = backward_propagation(a, caches, parameters)
# Update parameters.
parameters = update_parameters(parameters, grads)In Stochastic Gradient Descent, you use only 1 training example before updating the gradients.
当训练集很大时,SGD算法更快。But the parameters will "oscillate" toward the minimum rather than converge smoothly.下图是说明: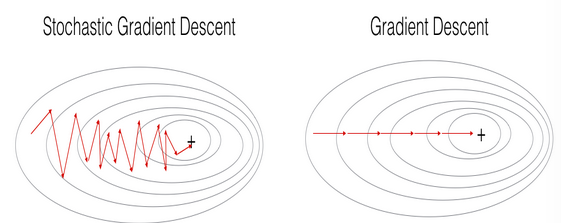
+表示代价函数的最小值。SGD达到收敛之前会有许多振荡,比起GD每一步的计算更快,因为每一次SGD只使用一个样本。
注意:实现SGD算法需要\(3\)个for循环:
- Over the number of iterations
- Over the \(m\) training examples
- Over the layers (to update all parameters, from \((W^{[1]},b^{[1]})\) to \((W^{[L]},b^{[L]}))\)
实际中,使用mini-batch梯度下降法(每个mini-batch使用训练样本个数为中间值,也就是既不使用整个训练集,也不使用单个样本,介于二者之间)会得到更快的结果。下图是说明: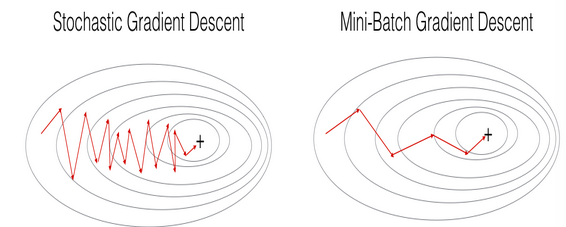 在
在SGD,GD和mini-batch GD三者之间的主要差异是:the number of examples you use to perform one update step.通常来说当训练集很大时,mini-batch梯度下降法的效果更好。
mini-batch 梯度下降法中 mini-batches的实现
实现mini-batches主要有两步:将数据集打乱和按照既定大小划分数据集。
- 将数据集打乱(Shuffle):如下图所示:
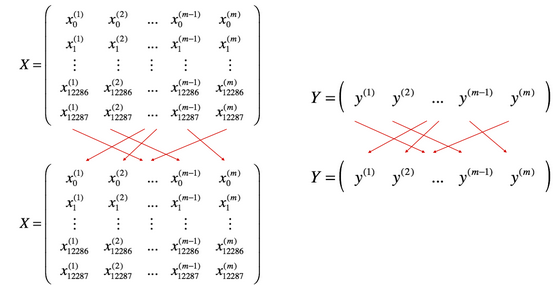
X和Y的每一列表示一个训练样本。X和Y的随机打乱要同步,也就是说随机打乱后X的\(i^{th}\)列对应于Y中\(i^{th}\)个标签(label)(和打乱之前相对应)。这一步确保数据集被随机划分为不同的mini-batches。 - 按照既定大小划分数据集(Partition):将随机打乱后的数据集
X和Y划分为大小为mini_batch_size的mini-batches。实际中训练样本集可能并不能保证每一个mini_batches的大小都是mini-batch_size,最后一个mini_batch可能更小,不过不用担心, 下图是说明: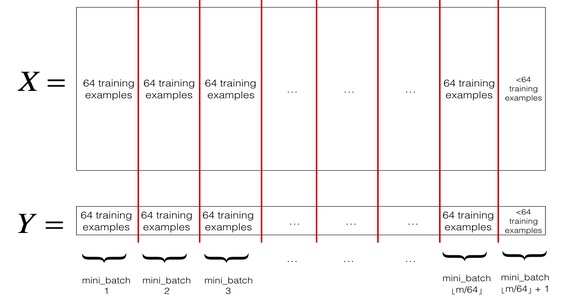
mini-batch 大小的选择
- 当训练样本集比较小,如\(m < 2000\)时,选择
batch梯度下降法; - 当训练样本集比较大时,选择
mini-batch梯度下降法,一般mini-batch的大小为\(2\)的幂次方,典型的大小有\(2^6, 2^7, 2^8, 2^9\); - 注意
mini-batch的大小要符合CPU/GPU的内存。
建议:编程实现 mini-batch 算法时,每一代( epoch )迭代都应该重新打乱数据集,再划分 mini-batch 。具体讨论参考这儿和这儿。
指数加权平均
指数加权平均(Exponentially Weight Average)的公式如下:$$S_t =\begin {cases}0 ,t=0 \\ \beta S_{t-1}+(1-\beta)Y_t ,t>1 \end {cases}$$其中\(Y_t\)为\(t\)下的实际值,\(S_t\)为\(t\)下的加权平均后的值,\(\beta \)为权重值。\(\beta \)越大相当于利用之前的数据越多(下面是解释)。
理解指数加权平均(EMA)
当\(\beta \)为\(0.9\)时,有:$$v _{100}=0.9v _{99}+0.1\theta _{100}$$$$v _{99}=0.9v _{98}+0.1\theta _{99}$$$$v _{98}=0.9v _{97}+0.1\theta _{98}$$$$\ldots$$展开得:$$v _{100}=0.1\theta _{100}+ 0.1\times 0.9\theta _{99}+ 0.1\times 0.9^2\theta _{98}+\ldots$$其中\(\theta _{i}\)表示第\(i\)个实际数据,且\(\theta \)前的系数之和为\(1\)(或近似为\(1\))。越旧的数据权值越小,如何给\(\beta \)一个直观的感觉呢?当权值\(\beta ^n\)小于\(\dfrac {1}{e}\)就可以说只关注了前\(n\)个数据。
根据公式:$$\lim _{\beta \to 0}(1-\beta )^{\dfrac {1}{\beta }}=\dfrac {1}{e}\approx 0.368$$可将\(\dfrac {1}{1-\beta}\)看成对过去多少个数据进行加权平均(近似)。
- 杂谈:如何理解当权值\(\beta ^n\)小于\(\dfrac {1}{e}\)就可以说只关注了前\(n\)个数据?
根据指数加权
(EMA)的公式可得到如下公式:$$EMS _\text {today}=\alpha [p _1 + (1-\alpha )p _2 +(1-\alpha )^{2}p _3 + \ldots]$$其中\(p _1\)是\(\text {value} _\text {today}\),\(p _2\)是\(\text {value} _\text {yesterday}\),以此类推。
进而可以得到:$$EMS _\text {today}=\dfrac {p _1 + (1-\alpha )p _2 +(1-\alpha )^{2}p _3 + \ldots}{1+(1-\alpha )+(1-\alpha )^2 +\ldots}$$考虑:$$\dfrac {1}{\alpha}=1+(1-\alpha )+(1-\alpha )^2 +\ldots$$下面考虑\(k\)天以后被忽略的权重所占的比重。
被忽略的权重之和为:$$\alpha [(1-\alpha )^{k} +(1-\alpha )^{k+1} +(1-\alpha )^{k+2} +\ldots ]$$$$=\alpha (1-\alpha )^{k}[1+(1-\alpha )+(1-\alpha )^2 +\ldots ]$$被忽略的权重之和所占的比例为:$$\begin{align} & \dfrac {\text {weight omitted by stopping after k terms}}{\text {total weight}}\\ ={} & \dfrac {\alpha [(1-\alpha )^{k} +(1-\alpha )^{k+1} +(1-\alpha )^{k+2} +\ldots ]}{\alpha [1+(1-\alpha )+(1-\alpha )^2 +\ldots ]}\\ ={} & (1-\alpha )^k \end{align}$$例如,如果我们要获取\(1-\dfrac {1}{e}\)的权重(也就是说用到的数据所占的权重占\((1-\dfrac {1}{e}\)),需要设置:$$(1-\alpha )^k =\dfrac {1}{e}$$解得$$k=\dfrac {\ln {(e^{-1})}}{\ln {(1-\alpha )}}\approx \dfrac {-1}{-\alpha}=\dfrac {1}{\alpha}$$其中分母\(\ln {(1-\alpha)}\)用泰勒公式展开获得近似。
(注:这个杂谈,各位看官只当看个笑话就行,我自己都没信服,如果有好的解释,麻烦联系我并告知,将不胜感激)
指数加权平均优点:只需要一行代码(不断覆盖旧值),占用内存少,效率高。
指数加权平均偏差修正
通常有:$$v _0 = 0$$$$v _1 =0.98 v _0 + 0.02\theta _1$$因此,可知\(v _1\)仅为第一个数据的\(0.02\)(或者\(1-\beta \)),显示偏差较大。修改公式为:$$v _t =\dfrac{\beta v _{t-1}+(1-\beta )\theta _1}{1-\beta ^t}$$当\(t\)增大时,\(\beta ^t \to 0\),所示当\(t\)较大时,修正偏差公式基本没作用,但在前期会帮助更好预测偏差。实际中,一般会忽略前期偏差的影响。
动量梯度下降法(Gradient Descent with Momentum)
动量梯度下降法(Gradient Descent with Momentum),运行速度几乎总是快于标准的梯度下降法,基本思想是计算梯度的指数加权平均,并利用该梯度更新权重。
动量梯度下降法的更新公式为(\(l =1, \ldots ,L)\):$$ \begin{cases}v_{dW^{[l]}} = \beta v_{dW^{[l]}} + (1 - \beta) dW^{[l]} \\W^{[l]} = W^{[l]} - \alpha v_{dW^{[l]}} \\ v_{db^{[l]}} = \beta v_{db^{[l]}} + (1 - \beta) db^{[l]} \\b^{[l]} = b^{[l]} - \alpha v_{db^{[l]}} \end{cases}$$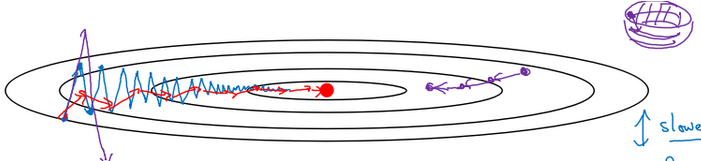 进行一般的梯度下降将会得到图中的蓝色曲线,存在上下波动,减缓了梯度下降的速度,只能用一个较小的学习率进行迭代。如果用较大的学习率,结果可能会像紫色曲线一样偏离函数的范围。
进行一般的梯度下降将会得到图中的蓝色曲线,存在上下波动,减缓了梯度下降的速度,只能用一个较小的学习率进行迭代。如果用较大的学习率,结果可能会像紫色曲线一样偏离函数的范围。
动量梯度下降法,通过累加过去的梯度值来减少抵达最小值路径上的波动,加速了收敛,在横轴方向下降得更快,从而得到图中红色的曲线。当前后梯度方向一致时,动量梯度下降能够加速学习;而前后梯度方向不一致时,动量梯度下降能够抑制震荡。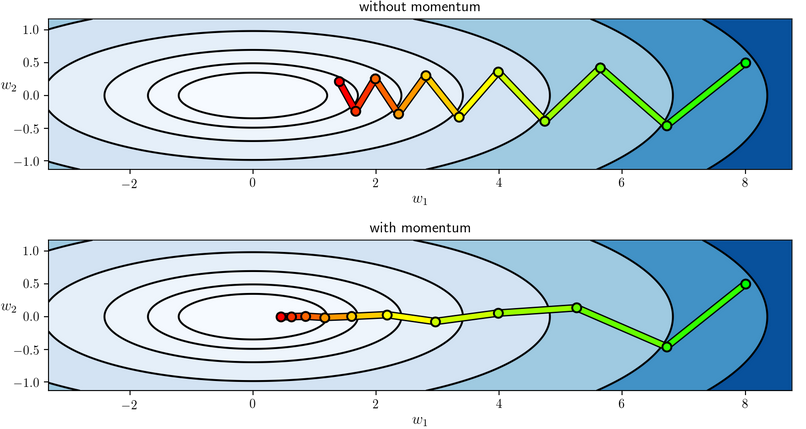
如何选择超参数\(\beta \)
- The larger the momentum \(\beta \) is, the smoother the update because the more we take the past gradients into account. But if \(\beta \) is too big, it could also smooth out the updates too much.
- Common values for \(\beta \) range from \(0.8\) to \(0.999\). If you don’t feel inclined to tune this, \(\beta =0.9\) is often a reasonable default.
- Tuning the optimal \(\beta \) for your model might need trying several values to see what works best in term of reducing the value of the cost function J.
RMSProp 算法
RMSProp 算法的更新公式为:$$s_{dW}=\beta s_{dW}+ (1-\beta )dW ^2$$$$s_{db}=\beta s_{db}+ (1-\beta )db ^2$$$$W=W-\alpha \dfrac {dW}{\sqrt {s_{dW}}+\varepsilon }$$$$b=b-\alpha \dfrac {db}{\sqrt {s_{db}}+\varepsilon }$$其中\(\varepsilon \)是一个实际操作(编程)添加的较小的数(例如\(10^{-8}\)为了防止分母太小导致数值不稳定。(上式中\(dW ^2\)操作是逐元素操作)
Adam 算法
Adam 优化算法( Adaptive Moment Estimation )基本上是将
Momentum和RMSProp算法结合在一起。在神经网络中是最有效的优化算法之一。
Adam算法工作流程如下:
- It calculates an exponentially weighted average of past gradients, and stores it in variables \(v\) (before bias correction) and \(v^{\text {corrected}}\) (with bias correction).
- It calculates an exponentially weighted average of the squares of the past gradients, and stores it in variables \(s\) (before bias correction) and \(s^{\text {corrected}}\) (with bias correction).
- It updates parameters in a direction based on combining information from “1” and “2”.
更新公式如下( \(l=1, \ldots, L)\):$$\begin{align} \begin{cases}v _{dW ^{[l]}}=\beta _{1}v _{dW ^{[l]}}+(1-\beta _{1})\dfrac{\partial {J}}{\partial {W^{[l]}}} \\ v _{dW^{[l]}} ^{\text {corrected}} = \dfrac {v _{dW ^{[l]}}}{1 - (\beta _{1}) ^t } \\ s _{dW ^{[l]}} = \beta _{2} s _{dW ^{[l]}} + (1 - \beta _{2}) (\dfrac{\partial {J} }{\partial {W ^{[l]}} }) ^2 \\ s _{dW ^{[l]}} ^{\text {corrected}} = \dfrac {s _{dW ^{[l]}}}{1 - (\beta _{2}) ^t} \\ W ^{[l]} = W ^{[l]} - \alpha \dfrac {v _{dW ^{[l]}} ^{\text {corrected}} }{\sqrt {s _{dW ^{[l]}} ^{\text {corrected}} }+ \varepsilon }\end{cases}& &\begin{cases}v _{db ^{[l]}}=\beta _{1}v _{db ^{[l]}}+(1-\beta _{1})\dfrac{\partial {J}}{\partial {b^{[l]}}} \\ v _{db^{[l]}} ^{\text {corrected}} = \dfrac {v _{db ^{[l]}}}{1 - (\beta _{1}) ^t } \\ s _{db ^{[l]}} = \beta _{2} s _{db ^{[l]}} + (1 - \beta _{2}) (\dfrac{\partial {J} }{\partial {b ^{[l]}} }) ^2 \\ s _{db ^{[l]}} ^{\text {corrected}} = \dfrac {s _{db ^{[l]}}}{1 - (\beta _{2}) ^t} \\ b ^{[l]} = b ^{[l]} - \alpha \dfrac {v _{db ^{[l]}} ^{\text {corrected}} }{\sqrt {s _{db ^{[l]}} ^{\text {corrected}} }+ \varepsilon }\end{cases}\end{align}$$其中 \(t\) 表示 Adam 算法 the number of steps。初始化设置如下:$$v _{dW ^{[l]}} =0, s _{dW ^{[l]}} =0, v _{db ^{[l]}} =0, s _{db ^{[l]}} =0$$
超参数选择
- \(\beta _1\)常用默认值 \(0.9\);
- \(\beta _2\)常用默认值 \(0.999\);
- \(\varepsilon \)不重要,不会影响算法表现,
Adam算法的作者建议为 \(10^{-8}\)。
学习率衰减
如果设置一个固定的学习率 \(\alpha \) ,在最小值点附近,由于不同的 batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
而如果随着时间慢慢减少学习率 \(\alpha \) ,在初期 \(\alpha \) 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 \(\alpha \) ,即减小步长,有助于算法的收敛,更容易接近最优解。
最常用的学习率衰减方法:$$\alpha =\dfrac {1}{1+ \text {decay_rate * epoch_num}} \times {\alpha _0}$$其中,decay_rate 为衰减率(超参数),epoch_num为遍历数据集的代数。还有其他的衰减方法,如指数衰减:$$\alpha =0.95^{\text {epoch_num}}\times \alpha _0$$其他方法可以参考视频教程。
注:实际中学习率衰减并不首先考虑。
超参数调试、Batch 归一化和编程框架
超参数调试
超参数重要性排序如下(参考)
- 最重要:学习率 \(\alpha \);
- 次重要:动量梯度下降法(Gradient Descent with Momentum)中的 \(\beta \),常设置为 \(0.9\);各隐藏层神经元数
hidden units;mini-batch size。 - 再次重要:
Adam优化算法超参数 \(\beta _1 \),\(\beta _2 \),\(\varepsilon \),常设为 \(0.9\)、\(0.999\)、\(10 ^{-8}\);神经网络层数layers;学习衰减率decay-rate。
调参技巧(建议)
- 随机选择点:在超参数组成的参数空间随机选择点进行实验;
- 由粗糙到精细:先粗略确定效果不错的小区域,再在小区域上精细实验。
给超参数选择合适的范围
对于学习率 \(\alpha \),用对数标尺(log)而不是线性标尺。例如 \(\alpha \)的范围是 \(0.0001\) 到 \(1\),利用对数标尺,在
python中实现如下:1
2r = -4 * np.random.rand()
a = np.power(10, r)对于 \(\beta\)(动量梯度下降法参数),可以考虑随机选取 \(1-\beta \)值。因为当 \(\beta \) 接近 \(1\) 时,即使 \(\beta \)有微小的变化,对结果的影响较大(当 \(\beta \) 取 \(0.9\) 相当于在 \(10\) 个值取平均,当 \(\beta \) 取 \(0.999\) 相当于在 \(1000\) 个值中取平均,\(\beta \)从 \(0.9\) 增加到 \(0.9005\) 对 \(\dfrac {1}{1-\beta }\) 基本没影响,但 \(\beta \) 从 \(0.999\) 增加到 \(0.9995\) 对 \(\dfrac {1}{1-\beta }\) 影响较大)
超参数调试实践
- 考虑数据变化或其他因素,建议每隔几个月重新评估超参数;
- 更具计算资源,训练模型方式:
panda(熊猫方式)与caviar(鱼子酱方式)。
Batch 归一化(Batch Normalization)
Batch 归一化 (Batch Normalization,简称 BN) 会使参数搜索问题变得容易,使神经网络对参数的选择更加稳定,超参数范围会更庞大,工作效果也很好,会使训练更容易。
之前的讨论中,对输入特征 X 进行了归一化处理。同样的思想可以用于处理隐藏层的激活值 \(a ^{[l]}\) ,从而可以加速参数 \(W ^{[l+1]}\) 和 \(b ^{[l+1]}\) 的训练。在实践中,经常选择归一化 \(Z ^{[l]}\)。公式如下:$$\mu =\dfrac {1}{m}\sum _{i=1} ^{m}z ^{(i)}$$$$\sigma ^{2} =\dfrac {1}{m}\sum _{i=1} ^{m}(z _i -\mu ) ^2$$$$z _{\text {norm}} ^{(i)} =\dfrac {z ^{(i)}-\mu }{\sqrt {\sigma ^2 +\varepsilon }}$$其中 \(m\) 为一个 mini-batch 包含的样本数,\(\varepsilon \) 是为了防止分母为 \(0\),常设为 \(10 ^{-8} \)。
归一化后,使得输入 \(Z ^{[l]}\) (针对一个 mini-batch )变为均值为 \(0\) ,方差为 \(1\) 。有时可能不想隐藏单元总是均值为 \(0\) ,方差为 \(1\),因此可以计算:$$\widetilde {z} ^{(i)} =\gamma z _{\text {norm}} ^{(i)} +\beta$$其中 \(\gamma \) 和 \(\beta \) 是模型的参数,需要学习。可以像更新神经网络的权重一样,用梯度下降法更新 \(\gamma \) 和 \(\beta \) 的值。
通过对 \(\gamma \) 和 \(\beta \) 的合理设置,可让 \(\widetilde {z} ^{(i)} \) 的均值和方差为任意值。在隐藏层,用 \(\widetilde {z} ^{(i)}\) 代替 \(z ^{(i)}\) 。
注:设置 \(\gamma \) 和 \(\beta \) 的原因是,如果各隐藏层的输入均值在靠近 \(0\) 的区域,即处于激活函数的线性区域,不利于训练非线性神经网络,从而得到效果较差的模型。
Batch 归一化(Batch Normalization)用于神经网络

Batch Normalization 经常使用在 mini-batch 上。在Batch Normalization 归一化时,参数中的 \(b\) 实际没有起到作用(归一化包括减去均值,常量不起作用),实际操作可以将参数 \(b\) 设置为 \(0\) 。
可以用梯度下降法、Adam 算法、RMSProp 算法、动量下降法等对参数 \(W ^{[l]}\),\(\beta ^{[l]}\),\(\gamma ^{[l]}\)进行更新。
BN有效的解释
Batch 归一化(Batch Normalization)效果好的原因主要有以下:
- 通过对隐藏层各神经元的输入做类似的归一化处理,提高神经网络训练速度;
- 使得前面层的权重变化对后面层的影响减弱,整体网络更加健壮。
关于上面第二点的解释:
实际中,如果训练样本和测试样本的分布不同(称之为Covariate Shift)使用 Batch Normalization 可以减小 Covariate Shift 带来的影响,让模型变得更具有鲁棒性。因为即使输入值改变了(不同的分布),由于 Batch Normalization 的作用,使得均值和方差不变(由参数 \(\gamma \) 和 \(\beta \) 决定),限制了输入变化对网络的影响,让学习变得容易些。Batch Normalization 让各层参数 \(W\) 和 \(b\) 间的耦合性降低,各层相对独立。
另外,Batch Normalization 还有轻微正则化作用。因为在每个 mini-batch 而非整个数据集上计算均值和方差,只由这一小部分数据估计得出的均值和方差会有一些噪声。因此最终计算出的 \(\widetilde {z} ^{(i)}\) 也有一定噪声,类似于 dropout,这种噪声会使得神经元不再特别依赖于任何一个输入特征。Batch Normalization 可以和 dropout 一起使用,以获得更强大的正则化效果。不要将 Batch Normalization 作为正则化的手段,而是当作加速学习的方式。
测试阶段的 Batch 归一化
使用之前的指数加权平均的方法来预测测试过程单个样本的 \(\mu \) 和 \(\sigma ^2 \)。
具体就是:对于第 l 层隐藏层,考虑所有 mini-batch 在该隐藏层下的 \(\mu ^{[l]}\) 和 \(\sigma ^{2[l]} \) ,然后用指数加权平均的方式来预测当前单个样本的 \(\mu ^{[l]}\) 和 \(\sigma ^{2[l]} \) 。这样实现了对测试过程单个样本的均值和方差估计。
Softmax 回归
可用于多分类问题。Softmax