内存对齐
内存对齐的原因
- 内存对齐后,提高CPU的访问速度。从程序员的角度,内存是一个一个字节组成,但是CPU把内存看成一块一块的,块的大小可以是2、4、8、16个字节,因此CPU读取内存的时候是一块一块进行的,块的大小称为内存读取粒度(memory granularity)
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常
例子:假设CPU要读取一个4字节大小的数据到寄存器中(假设内存读取粒度是4),分两种情况讨论
- 数据从0字节开始:直接将0-3四个字节完全读取到寄存器,结算完成了;
- 数据从1字节开始:首先先将前4个字节读到寄存器,并再次读取4-7字节的数据进寄存器,接着把0字节,4,6,7字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器,对一个内存未对齐的寄存器进行了这么多额外操作,大大降低了CPU的性能
内存对齐的规则
- 数据成员对齐规则:结构(struct或union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置为: min(#pragma pack()指定的数, 这个数据成员的自身长度)的倍数
- 结构体的总大小(sizeof的结果):必须是 min(#pragram pack() , 长度最长的数据成员) 的整数倍
例如:有如下结构体
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
struct A
{
short b;
double a;
char c;
};
int main()
{
A a;
cout << sizeof(a) << endl;
return 0;
}
输出结果为:241
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
struct A
{
short b;
double a;
char c;
};
int main()
{
A a;
cout << sizeof(a) << endl;
return 0;
}
输出结果为:111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
using namespace std;
struct A
{
double b;
short a;
char c;
};
int main()
{
A a;
cout << sizeof(a) << endl;
A* p = &a;
cout << "b: " << &(p->b) << endl;
cout << "a: " << &(p->a) << endl;
cout << "c: " << (int*)(&(p->c)) << endl;
return 0;
}
输出结果为:16,其中b的起始地址为0,a的起始地址为8, c的起始地址为101
2
3
416
b: 0x7fff96231e30
a: 0x7fff96231e38
c: 0x7fff96231e3a
大端和小端
对于跨越多字节的程序对象,需要建立两个规则:对象的地址是啥,及内存中如何排列这些字节。在几乎所有的机器上,对多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小地址。例如,一个int类型对象x的地址为0x100,也就是说地址表达式 &x 的值为0x100,那么x的4个字节被存储在内存的0x100、0x101、0x102和0x103
小端法:选择在内存中按照最低有效字节到最高有效字节的顺序存储对象(最低有效字节在前面的方式)
大端法:选择在内存中按照最高有效字节到最低有效字节的顺序存储对象(最高有效字节在前面的方式)
数据在内存中都是按照从内存的低地址开始到高地址的方式存放数据
例如int类型变量x的地址为0x100,其数据为0x01234567(高字节为0x01,低字节为0x67),则两种方式(大端与小端)的存储结果如下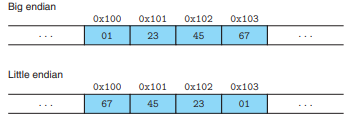
一旦选择特定的系统,那么字节顺序也就固定下来了
参考:结构体内存对齐用法
深入理解计算机系统